Dans le domaine de la relation client, les IA ont à présent démontré leur performance, et la majorité des consommateurs sont à présent satisfaits de leur prise en charge par un bot (voir note 1).

Alors que nombre de cas d’usages pourraient bénéficier d’intelligence artificielle, depuis quelque temps maintenant les organisations marquent le pas et les projets restent dans les cartons. Notre expérience approfondie parmi plus de 40 grandes entreprises et administrations françaises a mis en évidence le frein principal (voir note 2) : les indispensables données d’entraînement.
De nombreux acteurs ont bien compris le besoin du marché sur ce point (et on salue la très belle réussite des jeunes français d’HuggingFace). Mais si ces offres sont de plus en plus performantes pour des besoins génériques comme par exemple l’analyse de sentiments. Elles ne sont pas adaptées au traitement des demandes des clients des entreprises ou des usagers des services publics, parce que ces traitements nécessitent un entraînement très spécifique sur le métier et le vocabulaire interne de l’organisation.
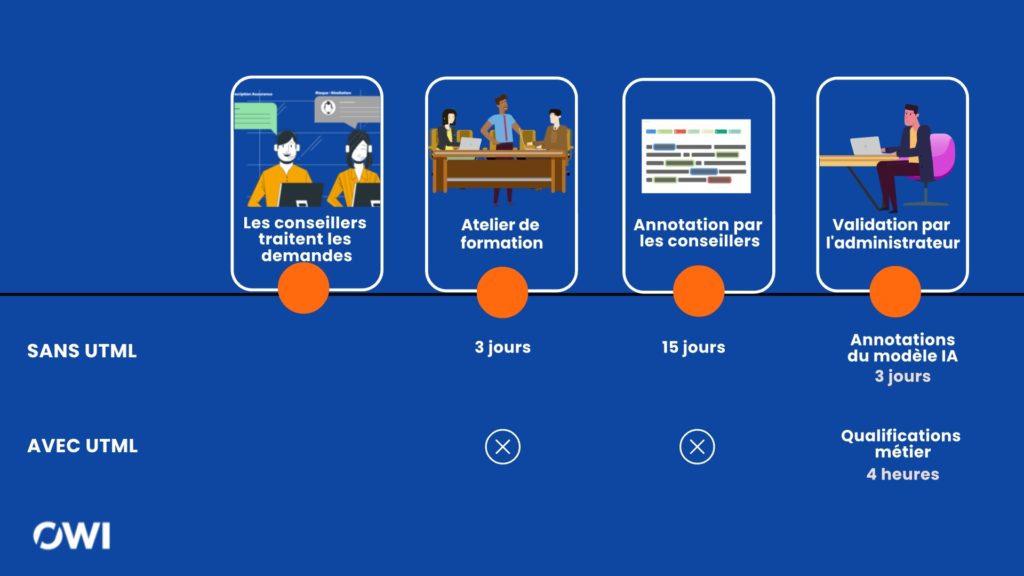
Bref, pas d’autre solution pour lancer un projet, jusqu’à ce jour, que d’obtenir des experts métier qu’ils annotent des messages. Or non seulement cela suppose un investissement important pour des personnes déjà très sollicitées (compter entre 30 et 60 jours.homme), mais en plus ces annotations doivent se faire selon des plans de classements qui, construits pour rendre une IA performante, ne parlent pas vraiment le langage des conseillers. Autrement dit, ce travail est coûteux, fastidieux, et d’une fiabilité assez souvent insuffisante (voir note 3).
Beaucoup de données sont présentes dans les applications internes : messages de clients dans les CRM, workflows… etc, auxquels sont associées des qualifications, des actions, des réponses. Alors pourquoi les modèles d’IA ne sont-ils pas entraînés directement à partir de ces informations ?
Prenons un exemple, dans l’assurance. Un assuré envoie un mail, qui est enregistré dans son historique. Un conseiller le qualifie en « demande d’attestation de rentrée scolaire », choisit un message de réponse, et son application déclenche automatiquement l’envoi du mail de réponse avec, en pièce-jointe, l’attestation demandée.
Les bénéfices d’UTML pour une entreprise ou une administration, c’est donc une utilisation directe de ses données, et aussi un apprentissage optimal (fiabilité et rapidité), puisque les messages se retrouvent annotés, sans perte de qualité, selon le formalisme du modèle d’IA qui a été choisi.
UTML cherche à « inverser » les calculs qui auraient été effectués à partir des résultats produits par l’IA pour obtenir les résultats choisis par les conseillers (note 4). Ces calculs sont de natures diverses, en particulier des règles métier ou la structure d’une base de connaissance : dans l’approche retenue sur UTML, nous remontons en niveau d’abstraction, ce qui assure non seulement des résultats précis, mais aussi des traitements plus rapides.

L’algorithme d’UTML suit la logique d’un « SAT Solver » appliqué aux résultats S.I. attendus :
L’utilisation de la logique formelle donne une grande flexibilité au processus : n’importe quel modèle ML de classification est compatible avec cette approche, en représentant les différentes classes possibles par des variables booléennes.
Note 1 : Adoption des bots par les consommateurs
85% des interactions client-marque impliqueront l’usage de chatbots en 2022.*
69% des clients préfèrent les chatbots intelligents à l’échange humain pour leur rapidité.**
74% des clients souhaitent avoir une conversation avec un humain pour des demandes plus complexes.
*Gartner (2018) cité dans Building the AI-powered customer center of the future by Customer Think (June 2018)
**Ubisend – Chatbot Survey (2017)
Note 2 : Principaux freins
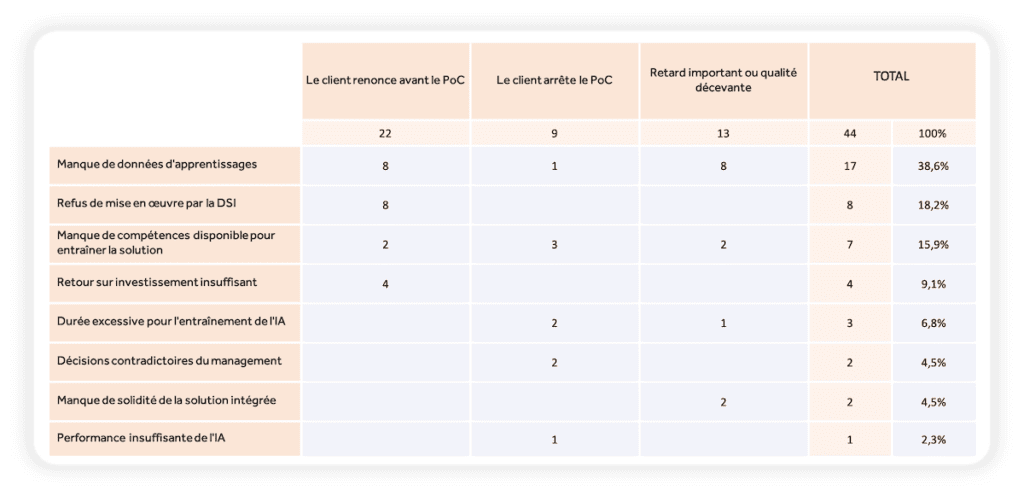
Analyse détaillée des principales causes, parmi les projets sur lesquels ont été rencontrées des difficultés
Note 3 : Produire des données d’entraînement : ce qui ne fonctionne pas
17 projets ont été en difficulté à cause du manque de données d’entraînement, et pourtant la difficulté de la transposition de données métier en annotations IA était anticipée.
Pour 11 de ces projets, nous avons évalué que c’est principalement la personne en charge de cette mission (trop technique), qui n’a pas réussi à bien comprendre le langage des métiers, ce qui s’est traduit par une démotivation générale et, au final, des annotations non fiables.
Pour 3 de ces projets, l’intervenant externe qui avait été missionné par le client à la place des métiers a fourni des annotations non conformes à la réalité des attentes de ces métiers.
Note 4 : Amélioration continue
Lorsque le modèle d’IA fonctionne déjà, en production ou en pilote, UTML va exploiter les résultats produits par votre solution d’IA et, en plus tagger précisément le ou les « nœuds » causes de l’erreur, pour fiabiliser le fonctionnement du machine learning en amélioration continue